enumSomeEnum:Int {
case aCase
}
enumAnotherEnum:Int {
case aCase
case bCase
}
print(MemoryLayout<SomeEnum>.size, MemoryLayout<AnotherEnum>.size, MemoryLayout<Int>.size)
structContentView:View {
@StateprivatevarisPopoverOpen=falsevarbody:some View {
Spacer()
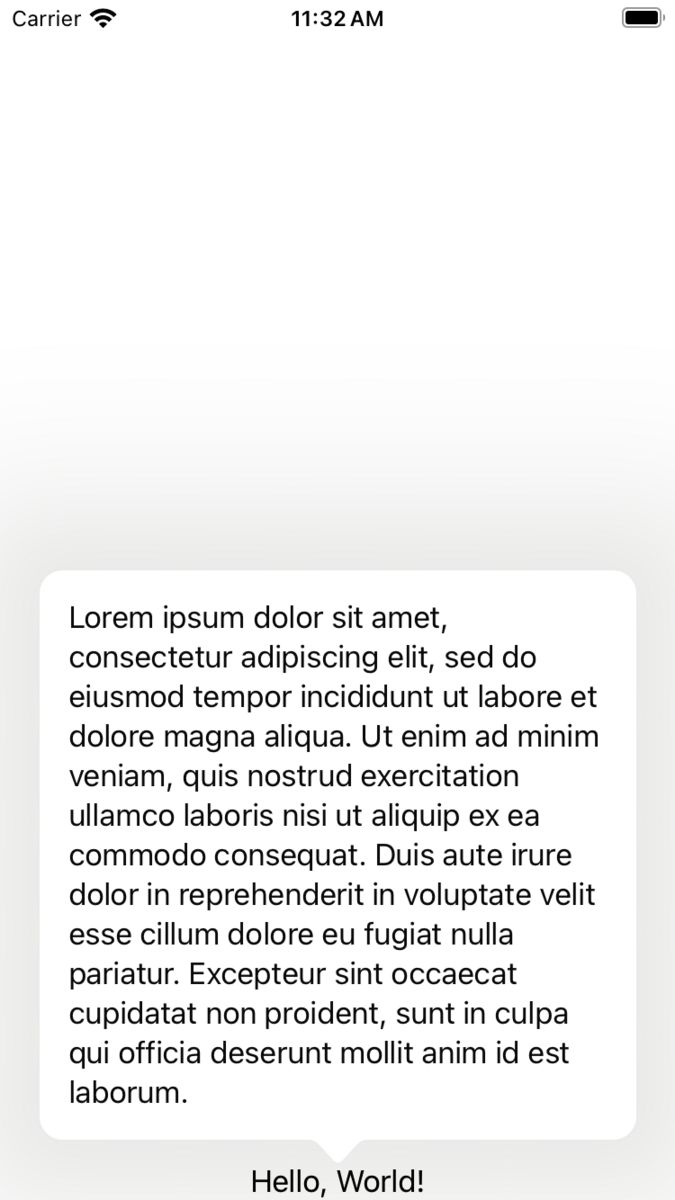
Text("Hello, World!")
.popover(isPresented:$isPopoverOpen) {
Text(""" Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. """
)
.fixedSize(horizontal:false, vertical:true)
.padding()
.presentationCompactAdaptation(.none)
}
}
}
structContentView:View {
@StateprivatevarisPopoverOpen=falsevarbody:some View {
Spacer()
Text("Hello, World!")
.popover(isPresented:$isPopoverOpen) {
PopoverContainer {
Text(""" Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. """
)
.fixedSize(horizontal:false, vertical:true)
.padding()
}
.presentationCompactAdaptation(.none)
}
}
}